Background
On a previous project, I was a part of, the client wanted to explore a chatbot application for its employees. The goal was for the chatbot to help increase the office’s productivity. Certain skills would be developed to enable swift access to popular actions such as opening a timesheet, password reset help, etc. The client also expressed a need for seamlessly adding new features, to the chatbot, when necessary. It was also decided that the chatbot would communicate with external services to fetch data. Taking what was discussed, we went to the drawing board to devise a plan on how to develop a scalable solution.
On top of the application having to be scalable, there was a decision to try and make the application as maintainable as possible too. Since this application will increase in size over time, it was key for us to lay down a foundation for how the chatbot would interact with classes and other services. As the architecture was finalized, it was apparent to us that there were critical dependencies on several Azure cognitive services. Thus, it became important that we try and ensure that the chatbot application would be maintainable to accommodate for those services. In order to accomplish this, a cascading approach to calling our dependencies was used.
Before I delve into the cascading approach, I want to spend some time talking about bots and the services used alongside them. Ultimately, the main goal of a bot is to accept a request from a user and process it based on what they ask for. For example, a user can ask a bot a question about company policies, the weather, recent documents they worked on or to open web pages.
LUIS
Now, in order to process those types of requests, Azure provides a couple of cognitive services to assist. One of these services is called LUIS (Language Understanding Intelligent Service). At a high level, LUIS determines an “intent” from statements (often called utterances) that you define in custom models for which you build and train. For example, LUIS can receive an utterance of “What’s the weather”. When an intent is found, there will be a confidence score (a value ranging from 0–1 inclusive) associated with the intent. This score just shows you how confident the service was in determining the intent. The closer the value is to 1, the more confident the service was, and the closer it is to 0 denotes how less confident the service was. In this example, the intent could be something like “GetWeather” with a 0.96 confidence score.
QnA Maker
Another cognitive service that is used with bot apps is QnA Maker. This service excels at housing data that is best suited for the question and answer pairs. The question and answer pairs are stored in what’s called a knowledgebase. A knowledgebase typically encapsulates data that pertains to a specific business domain (i.e. Payroll, HR, etc.). Like LUIS, QnA Maker utilizes machine learning, cognitive models, and confidence scores. When a QnA Maker knowledge base receives a question, it will use machine learning to determine if there is an answer associated with the question. A confidence score (ranging from 0-1 inclusive) will be associated with the results. If you would like to learn more about bot development and the different cognitive services offered in Azure, check out the links at the bottom of this post.
The Initial Approach
The chatbot solution included 1 LUIS service along with 3 separate QnA Maker knowledgebases. In our initial approach, we created intent definitions in LUIS that corresponded with each of our QnA Maker knowledgebases. We then trained LUIS to recognize if the user’s message was a question that could be answered by one of the knowledgebases. When messages came to the bot from the user, we would always send them to LUIS first. If it returned an intent that corresponded with one of our QnA Maker knowledgebases, we would then redirect the request to the identified knowledgebase. Then the knowledgebase would hopefully recognize the question and return an answer. That said, each call to a knowledgebase was dependent on the LUIS service correctly recognizing intents. This was not an ideal approach.
Having the QnA Maker knowledgebases dependent on the LUIS service was an issue. This meant that for a knowledge base to get a hit, the LUIS model would need to be properly trained and up to date. The LUIS model would need to be built and trained with data that closely matches that of each QnA Maker knowledgebase. That said, if the LUIS model is updated and it impacts a given QnA Maker knowledge base, then that knowledgebase would have to be updated and trained to contain the new data from the LUIS model. This approach would ensure the models from both LUIS and QnA Maker are in sync with each other. As you can probably see, this poses as a maintenance concern.
Cascading Solution
So, in order to alleviate this concern, a different approach was taken. The LUIS model would have no knowledge of any data from the QnA Maker knowledgebases and vice versa. That meant updating the LUIS model to remove data that corresponded to any of the QnA Maker knowledgebases. The same approach was done within each QnA knowledge base. This made it so both LUIS and QnA Maker were completely independent of each other. This led to having a cascading approach to calling each of our dependencies. As a result, this would resolve the imposing maintenance issue. (See image below)
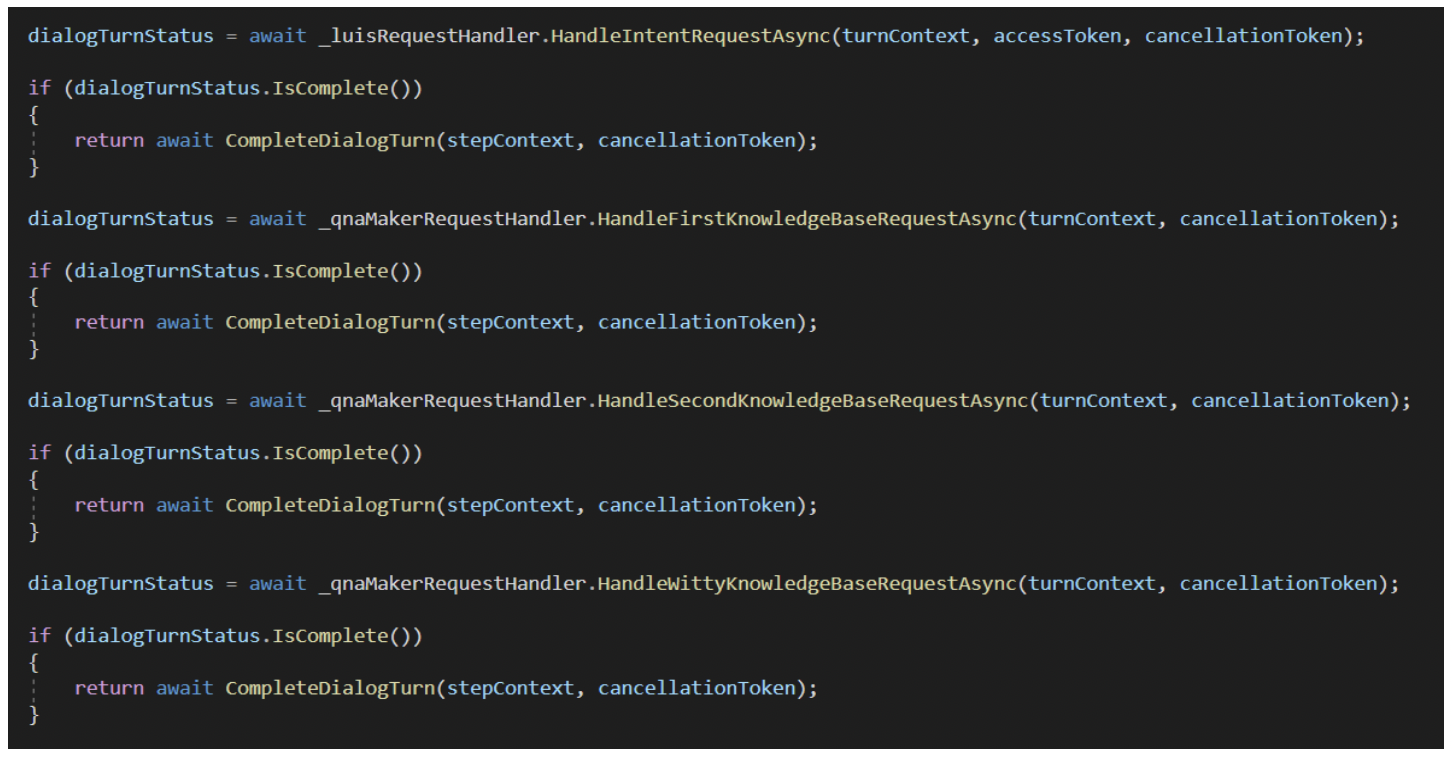
It is worth noting that we used Microsoft’s Bot Framework SDK for this solution, but the strategies you will see in this post can be used for any chatbot technology.
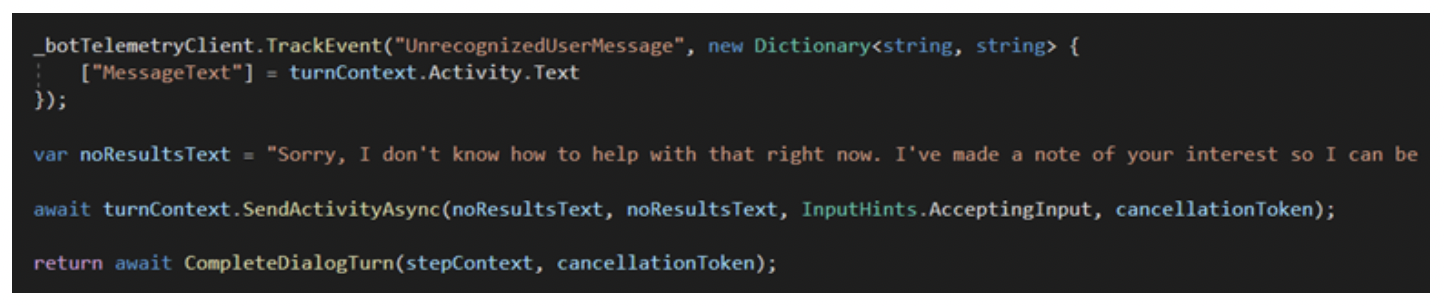
If the LUIS request handler was unable to handle the request, no problem! The next request handler would attempt to handle the request. This flow would proceed until one of the request handlers successfully handled a request. If none were successful, then the chatbot would tell our telemetry client, in our case Azure App Insights, to log the unrecognized user message. This would provide insight into model training opportunities. Finally, the chatbot would return a default message back to the client. (See image below)
Cascading Solution: Confidence Score Thresholds
Each result returned by a cognitive service holds a confidence score. This data proved to be very useful for the chatbot. In the LUIS and QnA Maker request handler classes, there was logic to determine if the returned confidence score met a given threshold. If the score was high enough, meaning the service was confident that it found the right data, then the given request handler can proceed with handling the request. If the score was found to be lower than the threshold, then the request handler does not continue with handling the request. (See image below of a sample method to handle an intent request)
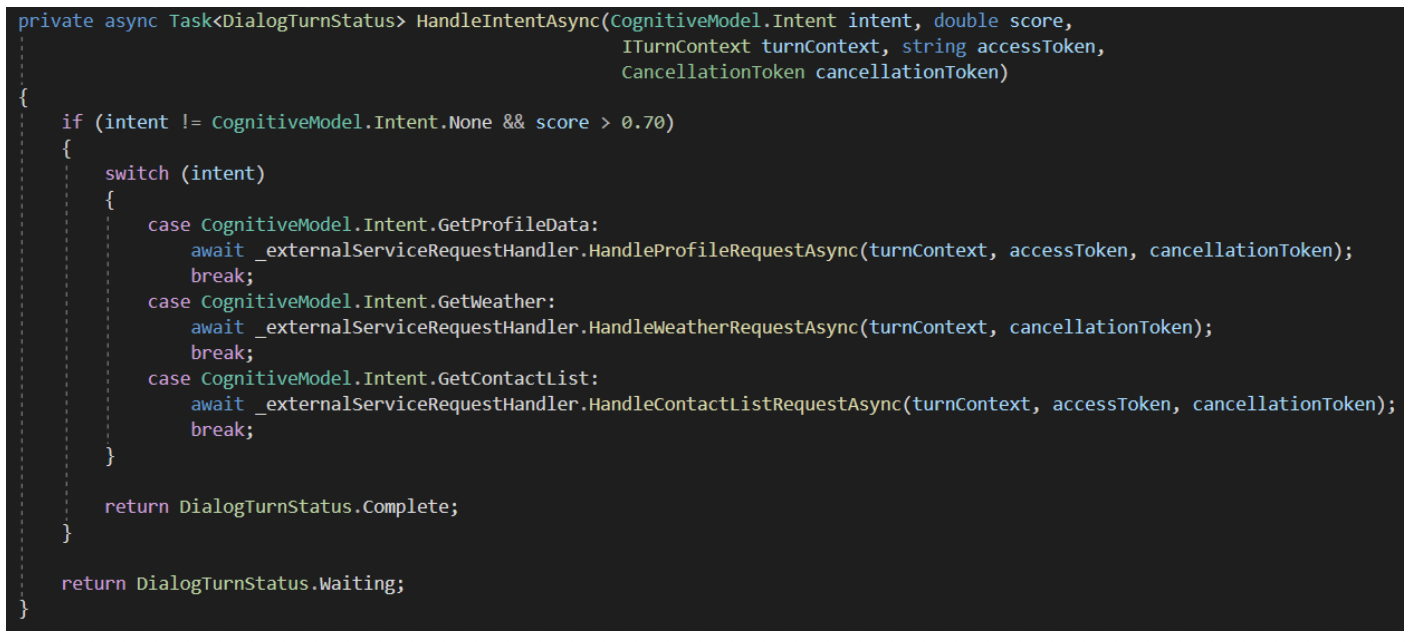
Instead, the next request handler will be told to execute. Having this implementation in place helps be explicit with defining an acceptable confidence score. That said, determining a confidence score threshold depends on how extensive your cognitive models are. If your cognitive models account for various phrases and spelling of keywords, then your cognitive services will have an easier time identifying intents/answers. In practice, I found that 0.70 and 0.75 to be satisfactory threshold values.
Cascading Solution: Dialog Turn Status
The final piece to the cascading solution was handling the progression or conclusion of a dialog turn. Think of a dialog turn as a face-to-face conversation. You might initiate the conversation with a question, which is a turn. Then, the other person would answer your question. That is also a turn. This can continue until the conversation ends. Conversations with a bot follow a similar flow. When it’s the bot’s “turn” to reply to the client, it performs its logic then responds. Below is a diagram, provided by Microsoft, illustrating the high-level nature of a conversation with a bot.
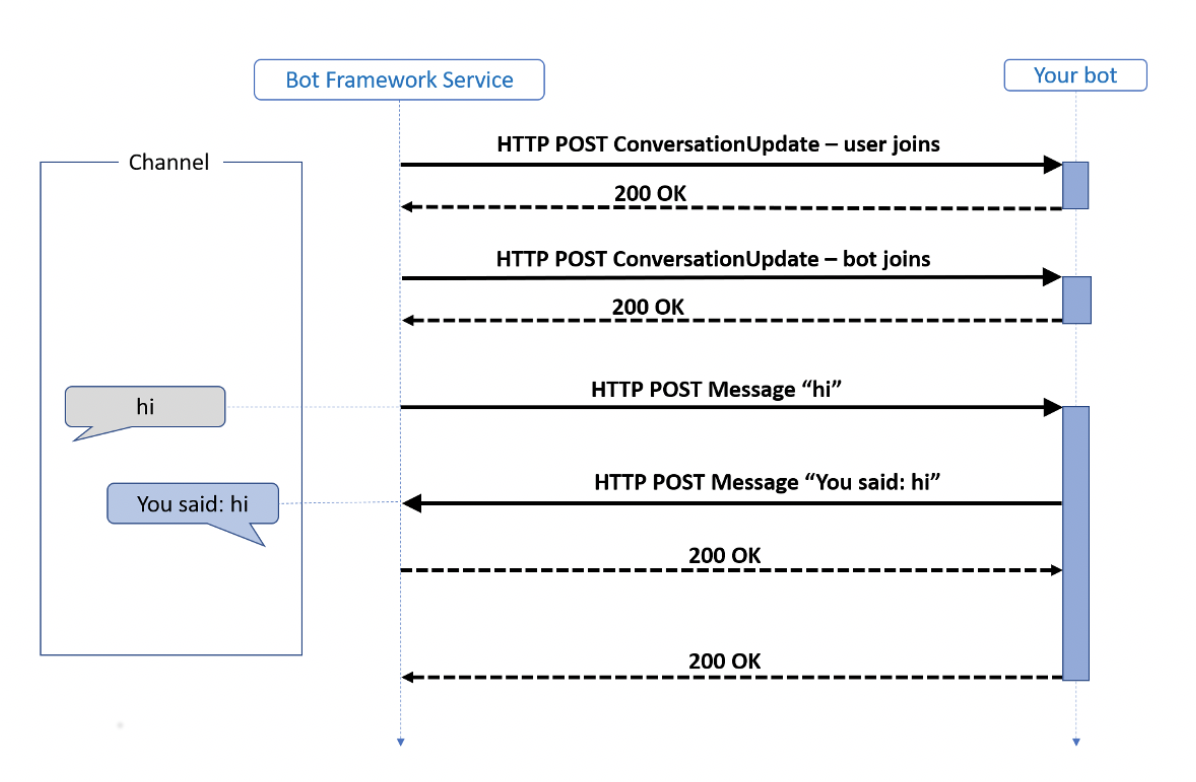
Image from: https://docs.microsoft.com/en-us/azure/bot-service/bot-builder-basics?view=azure-bot-service-4.0&tabs=csharp
In the cascading solution, we were explicit when the bot’s turn was over or when it should continue processing the request. Ultimately, when the chatbot found an answer to the user’s question or request, we would tell the chatbot that its turn is complete. On the contrary, we had several scenarios where we told the chatbot to keep its turn going. One scenario was if LUIS did not return an intent or if the confidence score was below our threshold. Another one was if a QnA Maker knowledge base did not find an answer to the given question passed to it. After each request handler executes, there is a check to verify if the turn is complete or not.
Closing Thoughts
The cascading approach for handling calls to the different services/knowledgebases was a huge win for this bot application. It offers clear, concise, and manageable code. Every LUIS and QnA Maker cognitive model is independent of each other and each request handler is independent of each other as well. In addition, the implementation of confidence score thresholds ensured that we were explicit with how we further processed client requests. Finally, adding progression and termination logic for a dialog turn certified that it would be appropriately processed. This whole approach helped paint a clear picture of what our chatbot was doing.
Links:
- Microsoft Bot Framework: https://dev.botframework.com/
- How Bots Work: https://docs.microsoft.com/en-us/azure/bot-service/bot-builder-basics?view=azure-bot-service-4.0&tabs=csharp
- LUIS: https://www.luis.ai/home
- QnA Maker: https://www.qnamaker.ai/