The recent #AWS and #Azure outages over the past two weeks are a good reminder of how seemingly simple problems (failure of power source or incorrect script parameter) can have a wide impact on application availability.
Look, the cloud debate is largely over and customers (commercial, government agencies, and startups) are moving the majority of their systems to the cloud. These recent outages are not going to slow that momentum down.
That said, all the talk of 3-4-5 9s of availability and financial-backed SLAs has lulled many customers into expecting a utility-grade availability for their cloud-hosted applications out of the box. This expectation is unrealistic given the complexity of the ever-growing moving parts in a connected global infrastructure, dependence on third-party applications, multi-tenancy, commodity hardware, transient faults due to a shared infrastructure, and so on.
Unfortunately, we cannot eliminate such cloud failures. So what can we do to protect our apps from failures? The answer is to conduct a systematic analysis of the different failure modes, and have a recovery action for each failure type. This is exactly the technique (FMEA) that other engineering disciplines (like civil engineering) have used to deal with failure planning. FMEA is a systematic, proactive method for evaluating a process to identify where and how it might fail and to assess the relative impact of different failures, in order to identify the parts of the process that are most in need of change.
In 2004, researchers at Berkeley took the idea of FMEA and extended it to software systems through the notion of Recovery Oriented computing (ROC). ROC is embracing failures, coping strategies. It emphasized Time to Recovery and chaos testing strategies (made popular in recent years by Netflix’s Chaos Monkey tool).
In recent years, Microsoft’s Trustworthy Computing Group built on the concept of ROC to come up with a resilience approach called Resilience Modeling and Analysis (RMA) for cloud services. RMA recommends that we address reliability issues early in design and prioritize reliability-related work efforts. RMA is comprised of four steps shown in the diagram below:

Document: Creates a diagram to capture resources, dependencies, and component interactions.
Discover: Identifies failures and resilience gaps.
Rate: Performs impact analysis.
Act: Produces work items to improve resilience.
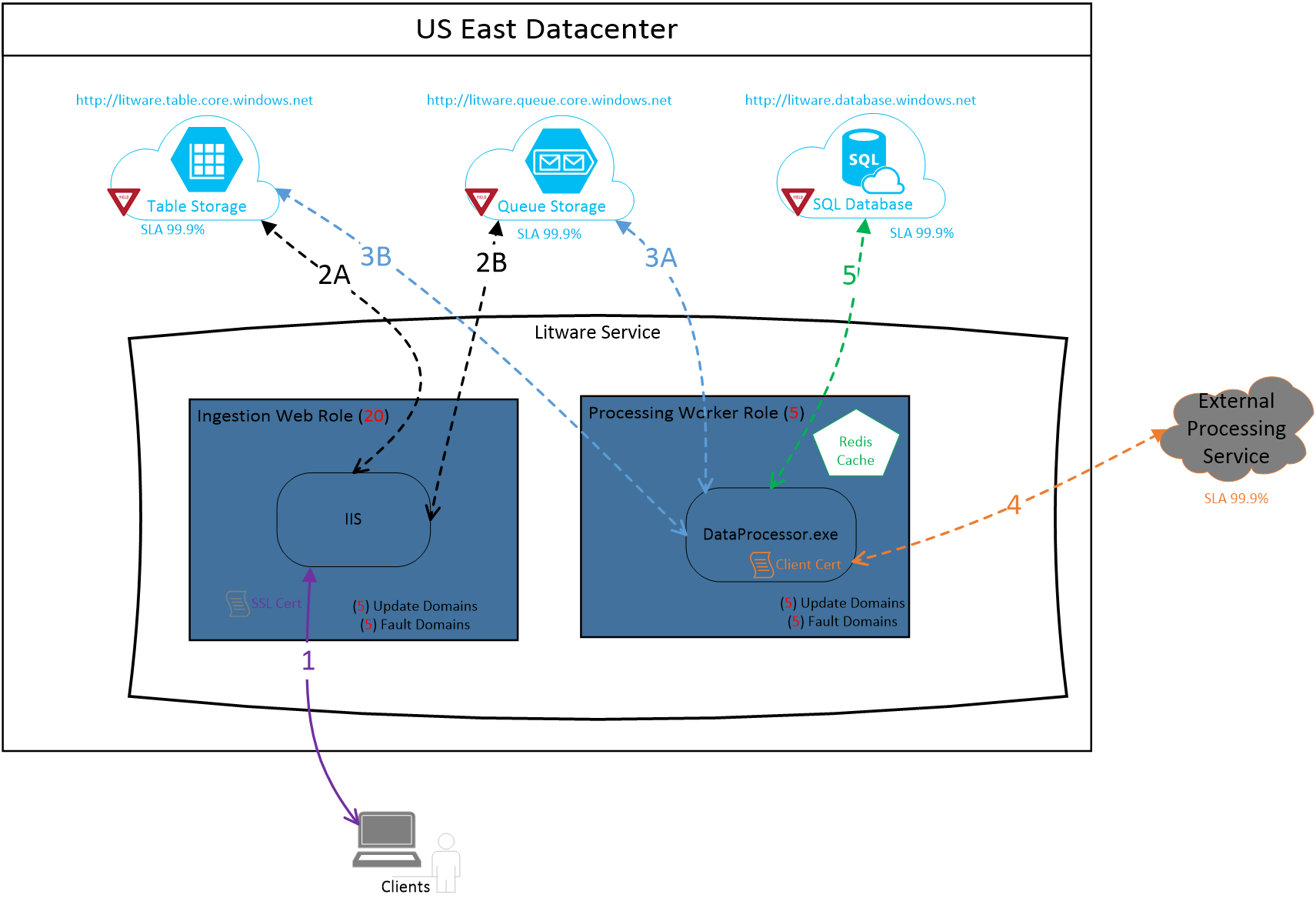
The most important step in conducting the RMA, is to generate a Component Interaction Diagram (CID). CID is similar to a component diagram that most teams use today, except CID adds important aspects related to application reliability. CID includes all dependencies with the appropriate interactions between them. CID also depicts many shapes and connections to provide visual cues that will help teams analyze failures later in the process. As an example, the CID depicted below depicts i) certificates (a frequent source of failure), ii) a yield sign that the resource may be subjected to throttling and may lead to transient failures, iii) cache instances, iv) fault domains, v) external dependencies and SLAs.
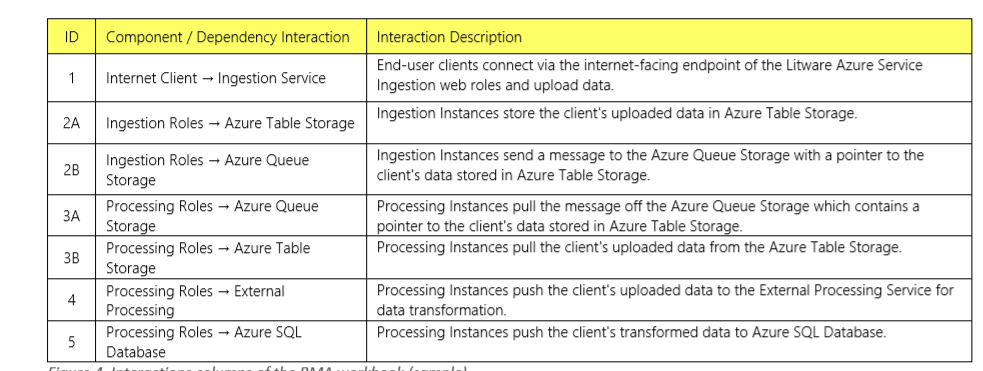
 The next step is to convert the above diagram into a RMA workbook (shown below) to create a list on interactions. These interactions can help enumerate the failure types encountered during each interaction.
The next step is to convert the above diagram into a RMA workbook (shown below) to create a list on interactions. These interactions can help enumerate the failure types encountered during each interaction.
The final step is to analyze and create a record of the effects that could result from each of the aforementioned failure types, within the business context. The goal is to consider these failure types in the context of the following questions:
- What will be the discernible effects to the user or business-critical process?
- Will this outage be a minor annoyance on performance impact, or will this outage be something that prevented key user scenarios from being completed?
- What will be the depth of the impact?
- How large will the scope of the impact be? Would only a few customers or transactions be affected, or will the scope of the impact be widespread? What will the breadth of impact be?
- How long will it take a person or automated system to become aware of the failure? What will be the approximate time to detect (TTD)?
- Once detected, how long will it take to recover the service and restore functionality? What was the time to recover (TTR)?
Ultimately, the answers to the above questions can help assess the risk and come up with appropriate mitigation strategies.
Here is a short video that walks you through the process of applying RMA to a distributed application built using Azure Services.
For a detailed overview of FMEA & RMA in the context of cloud application, please watch the recording of this Ignite session.
In summary, incorporate RMA into your cloud application development lifecycle: model failures and the effects of those failures, decide which failures must be addressed and make the necessary engineering investments to mitigate high-priority risks.
Top Image Copyright: worac / 123RF Stock Photo