As part of one of my projects, I was asked to research methods of transferring large amounts of data (> 1 Terabyte) between client-owned S3 buckets. Several suitable techniques are available. They include:
- Running parallel uploads using the AWS command-line interface (CLI)
- Using an AWS SDK (Source Development Kit)
- Using cross-region or same-region replication
- Using S3 batch operations
- Using S3DistCp with Amazon EMR
- Using AWS DataSync
Some of these methods, such as copying files and directories using the AWS CLI or an AWS SDK, also work well for datasets smaller than one terabyte (1TB). The content of this blog post was largely derived from this official AWS article on the subject.
Also, note that you will likely run into some issues, particularly for using the AWS CLI directly or using a custom SDK like Boto3 for Python, particularly around permissions on the source bucket or the destination bucket. This article from AWS covers many potential failure states.
Running Parallel Uploads Using the AWS Command-line Interface (AWS CLI)
The simplest method for direct S3-S3 copying (apart from using AWS’s GUI interface for one-time manual transfers) is the AWS command-line interface. This works for small, individual files and much larger sets of larger files. The official AWS CLI reference index is here, specifically for AWS CLI S3 commands.
If I wanted to copy all files with the .jpg extension in a folder at the root of my source S3 bucket named “foo_imgs” to a folder named “foo_destination” in my destination S3 bucket, the command would be:
![]()
The basic format of the command is “aws cp,” followed by the source bucket and directory and then the destination bucket and directory. You include the “–recursive” flag whenever you have more than one file to copy – otherwise, the “cp” command only copies a single file.
If your project requires filtering for or against specific items, you can specify which folders and items to include by using the “–include” and “–exclude” parameters with each command. In the example above, “—exclude” excludes all items in the source bucket, and then, crucially, the “—include” flag includes all items with the .jpg extension. It may seem strange or counter-intuitive, but only having the “—include” flag will not work because, by default, all files are included. You would be including the files you’re filtering for, along with everything else. Adding “—include” will only re-include files that the “—exclude” flag has excluded, and if you never specified anything for “—exclude”, then there is no filtering that happens. You have to use “—include” and “—exclude” in tandem. Also, note that these parameters are processed on the client-side, so your local system’s resources will affect how well this method works.
To run parallel copy operations, you can open multiple instances in your terminal of the AWS CLI and then run the AWS cp command in each, changing the “—include” and “—exclude” flags for each instance. Suppose you have a set of files in a directory whose names begin with 0 through 9. The first terminal instance would copy filenames that start with 0 through 4, and the second terminal instance would copy those beginning with 5-9, and so on. Each copy operation would use a single thread in its terminal instance to copy the range of objects specified for it.
First terminal instance:
![]()
Second terminal instance:
![]()
Using an AWS SDK (Source Development Kit)
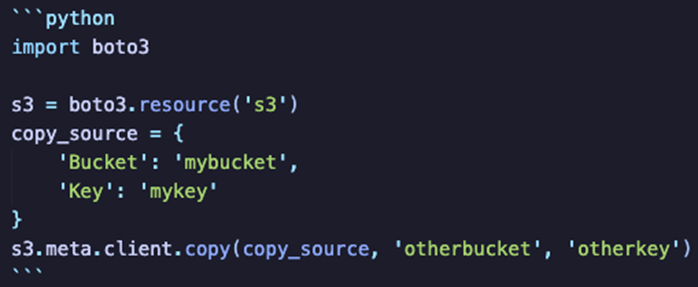
You can build a custom application using a source development kit to perform the data transfer. The idea here is that a custom application might be more efficient at performing a transfer at the scale of hundreds of millions of objects or if you want to automate the process. For example, on our project, we used the SDK for Python, Boto3.
Here is a sample Boto3 copy operation:
Using Cross-Region Replication or Same-Region Replication
Setting up either Cross-Region replication or Same-Region replication on a source S3 bucket will automatically replicate new uploads from the source bucket to a destination bucket. You can filter which objects will be replicated using a prefix or a tag. One limitation of this method is that it only replicates new objects, so you would have to empty both buckets, set up Cross-Region or Same-Region replication, and then upload objects into your source S3 bucket to test this method out.
Using S3 batch operations
You can also use Amazon S3 batch operations to copy multiple objects with a single request. You should particularly consider using this method over a method like the “aws cp” operation if your bucket contains more than 10,000,000 objects, although there are caveats to batch copying as well. You create a batch operation job in which you specify which objects to operate on using either an Amazon S3 inventory report or a CSV manifest file. Then Amazon S3 batch operations will call the API to operate. When the batch operation job is complete, you will receive a notification, and you can choose to receive a completion report about the job.
Using S3DistCp with Amazon EMR
Here is an existing definition that is already perfectly succinct: “Amazon EMR is a cloud big data platform for running large-scale distributed data processing jobs, interactive SQL queries, and machine learning (ML) applications using open-source analytics frameworks such as Apache Spark, Apache Hive, and Presto.”
There are occasions when you may want to copy S3 data to a Hadoop Distributed File System (HDFS) housed on an Amazon EMR cluster. Or you might want to move a large amount of data between S3 buckets or regions, and in these cases, the “aws cp” operation might not be feasible. Amazon EMR includes a utility called S3DistCp, an extension of DistCp, which is often used to move data with the Hadoop ecosystem. S3DistCp is optimized to work with Amazon S3 and adds several features.
S3DistCp performs parallel copying of large volumes of objects across Amazon S3 buckets. S3DistCp first copies the files from the source bucket to worker nodes in an Amazon EMR cluster. S3DistCp includes several use cases, such as copying or moving files without transformation, copying and changing file compression during the copy process, and copying files incrementally. View a complete list here.
Be aware, however, that an additional cost is incurred because you are using Amazon EMR. Here is a link to Amazon EMR’s pricing page, which includes a comparison table of Amazon EC2 on-demand price rates alongside Amazon EMR price rates. You pay a per-second rate for every second you use, with a minimum of one minute of usage.
Using AWS Datasync
Finally, you can also use AWS Datasync to move large file sets between buckets. View a numbered list of steps to do so here. As noted at the bottom of that documentation, you will be charged an additional fee for using AWS Datasync at $0.0125 per gigabyte (GB). You can find more information and cost breakdowns for sample use cases here. Additionally, here is a link listing AWS Datasync quotas and limits.
Conclusion
The solutions listed in this article encompass many different use cases. My project used the first and second methods: running the AWS CLI through Python’s Boto3 library. Although we didn’t end up opting for the last four solutions, you may find that one of them fits your project’s needs.