



Defining your cloud computing infrastructure as code (IAC) is becoming an industry standard for enterprise IT teams to scale effectively as their development teams and applications grow.
Terraform, by Hashicorp, is an infrastructure as code tool that lets you define both cloud and on-prem resources using human-readable configuration files that you can version, reuse, and share across your various projects and development teams.
This post will focus on several methods and patterns to make the most out of your terraform code, explicitly focusing on keeping your terraform code and configurations organized and easy to maintain; we will strive to implement DRY principles wherever possible. As a result, this post assumes you’ve worked with Terraform before and have a general understanding of how to use it. If you want to know more about Terraform and what it can offer, look at Hashicorp’s website. Also, check out this video by Hashicorp’s cofounder for a short summary of what Terraform can offer.
Modularization & Terraform Registry
Terraform has a few different offerings that provide various features. The most basic of which is open source, the Terraform CLI. Although Terraform CLI is an excellent tool, it is significantly more helpful when best practices are implemented.
One of the first things to do is organize your terraform code. Break it apart into child modules or components that encapsulate smaller pieces of your infrastructure. Instead of having one module file that provisions all of your resources, break up your architecture into several components (i.e., AppService plan, AppService, storage account, Redis cache) and reference them as dependencies in your encapsulating module (ex. main.tf).
Hashicorp also gives you access to their public Terraform registry for various providers like AWS and Azure. The public registry already has re-usable modules for the simplest cloud resource blocks for you to extend and utilize.
Although these pre-defined modules exist to standardize resource naming conventions, cloud computing sizing/scaling, and other restrictions, you may want to impose on your development teams to create modules that utilize modules in the public Terraform Registry. Create them with distinctly defined validation parameters for input variables.
If you want to read more about creating Terraform modules, check out this blog post by the creators of Terragrunt, as well as Hashicorp’s documentation.
Now the question arises: where do I keep the code for my child modules to be easily distributable, re-usable, and maintainable? Creating these child modules and storing the code within the application code repository creates some disadvantages. What if you want to re-use these sub-modules for other repositories or different projects? You’d have to duplicate the child module code and track it in several places. That’s not ideal.
To address this, you should utilize a shared registry or storage location for your child modules to reference them from multiple repositories and even distribute different versions to different projects. This would involve moving each submodule to its individual repo to be maintained independently and then uploading it to your registry or central storage location. Acceptable methods that Terraform can work with are:
- GitHub
- Bitbucket
- Generic Git, Mercurial repositories
- HTTP URLs
- S3 buckets
- GCS buckets
See the Terraform documentation on module sources for more information.
Utilizing these methods allows you to maintain your sub modules independently and distribute different versions that larger applications can choose to inherit. You might go from Terraform projects like this:
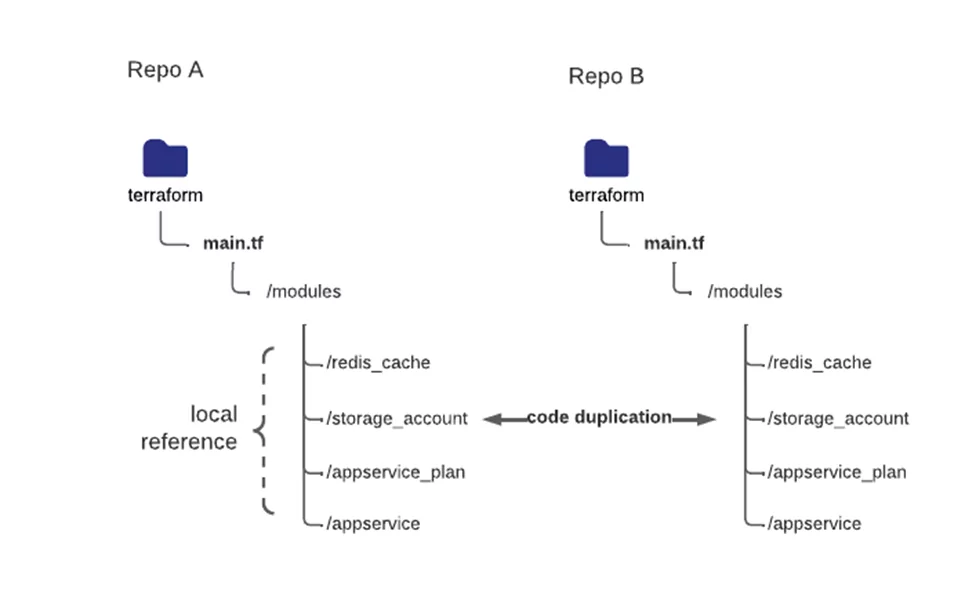
to this:
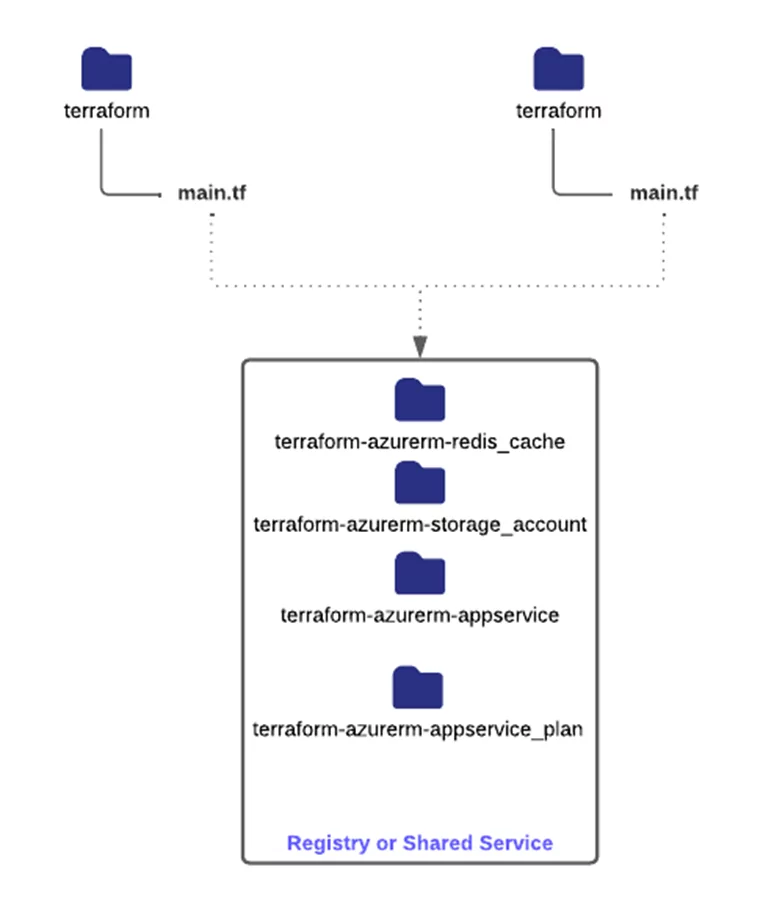
Terragrunt
Preface
Utilizing registries to modularize your infrastructure is only a small part of the improvements you can make to your Terraform code.One of the significant concepts of Terraform is how it tracks the state of your infrastructure with a state file. In Terraform, you need to define a “remote state” for each grouping of infrastructure you are trying to deploy/provision. This remote state could be stored in an S3 bucket, Azure Storage account, Terraform Cloud, or another applicable service. This is how Terraform knows where to track the state of your infrastructure to determine if any changes need to be applied or if the configuration has drifted away from the baseline that is defined in your source code. The organization of your state files is essential, especially if you are managing it yourself and not using Terraform Cloud to perform your infrastructure runs.
In addition, you must keep in mind that when your development teams and applications grow. You will frequently need to manage multiple developments, testing, quality assurance, and production environments for several projects/components simultaneously; the number of configurations, variable files, CLI arguments, and provider information will become untenable over time.
How do you maintain all this infrastructure reliably? Do you track all the applications for one tier in one state file? Or do you break them up and track them separately?
How do you efficiently share variables across environments and applications without defining them multiple times? How do you successfully apply these terraform projects in a continuous deployment pipeline that is consistent and repeatable for different types of Terraform projects?
At one of our current clients, we were involved with onboarding Terraform as an Infrastructure as Code (IaC) tool. However, we ran into many challenges when trying to deploy multiple tiers (dev, test, stage, production, etc.) across several workstreams, specifically in a continuous manner within a deployment pipeline.
The client I work for has the following requirements for the web UI portion of the services they offer (consider Azure Cloud provider for context):
- each tier has *six applications* for different areas of the United States
- *Each application* has a web server, a Redis cache, app service plan, a storage account, and a key vault access policy to access a central key store
- Development and test tiers are deployed to a single region.
- Applications in the development and test tier both share a Redis cache
- Applications in Staging and production environments have individual Redis caches
- Stage and production environments are deployed to two regions, east and central.
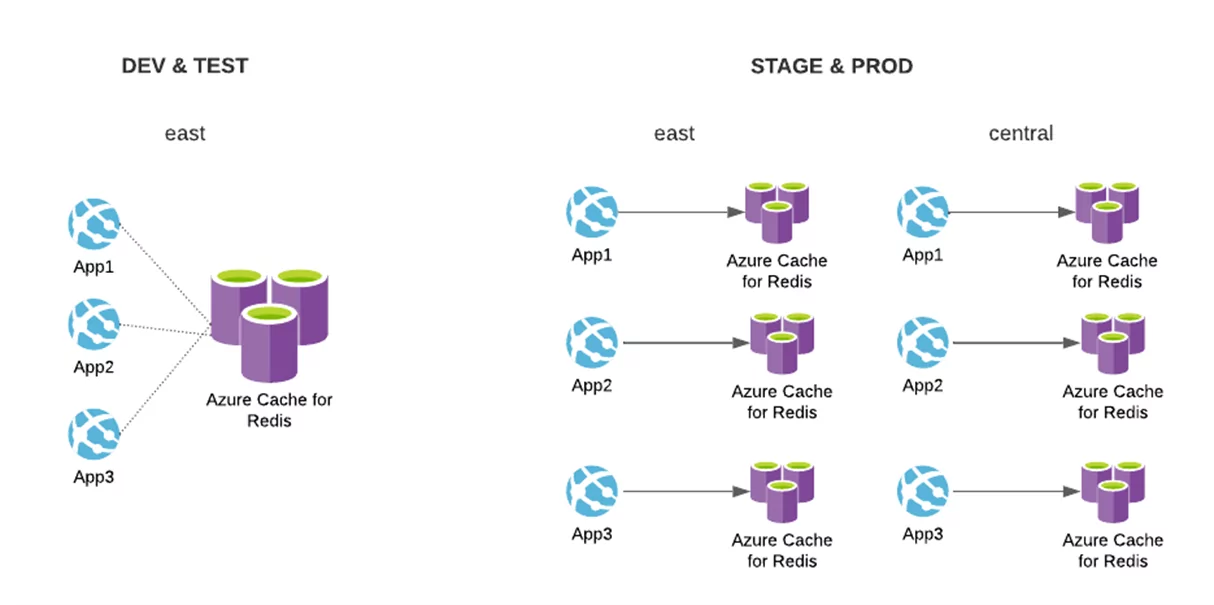
Stage and Production tiers have up to 48 resources, respectively; the diagram above only represents three applications and excludes some services. Our client also had several other IT services that needed similar architectural setups; most projects involved deploying six application instances (for each service area of the United States), each configured differently through application settings.
Initially, our team decided to use the Terraform CLI and track our state files using an Azure Storage Account. Within the application repository, we would store several backend.tf files alongside our terraform code for each tier and pass them dynamically to terraform init –backend-config= when we want to initialize a specific environment. We also passed variable files dynamically to terraform [plan|apply|destroy] –var-file= to combine common and tier-specific application setting template files. We adopted this process in our continuous deployment pipeline by ensuring the necessary authentication principals and terraform CLI packages were available on our deployment agents and then running the appropriate constructed terraform command in the appropriate directory on that agent.
This is great but presented a few problems when scaling our process. The process we used initially allowed developers to create their own terraform modules specific to their application, utilizing either local or shared modules in our private registry. One of the significant problems came when trying to apply these modules in a continuous integration pipeline. Each project had its own unique terraform project and its own configurations that our constant deployment pipeline needed to adhere to.
Let’s also consider something relatively simple, like the naming convention of all the resources in a particular project. Usually, you would want the same-named prefix on your resources (or apply it as a resource tag) to visually identify what projects the resources belong to. Since we had to maintain multiple tiers of environments for these projects (dev, test, stage, prod), we wanted to share this variable across environments, only needing to declare it once. We also wanted to declare other variables and optionally override them in specific environments. With the Terraform CLI, there is no way to merge inputs and share variables across environments. In addition, you cannot use expressions, functions, or variables in the terraform remote state configuration blocks, forcing you to either hardcode your configuration or apply it dynamically through the CLI; see this issue.
We began to wonder if there was a better way to organize ourselves. This is where Terragrunt comes into play. Instead of keeping track of the various terraform commands, remote state configurations, variable files, and input parameters we needed to consolidate to provision our terraform projects. What if we had a declarative way of defining how our terraform project was configured? Terragrunt is a minimal wrapper around Terraform that allows you to dynamically assign and inherit remote state configurations, provider information, local variables, and module inputs for your terraform projects through a hierarchal folder structure with declarative configuration files. It also gives you a flexible and unopinionated way of consolidating everything Terraform does before it runs a command. Every option you pass to Terraform can be specifically configured through a configuration file that inherits, merges, or overrides components from other higher-level configuration files.
Terragrunt allowed us to do these important things:
- Define a configuration file to tell what remote state file to save based on application/tier (using folder structure)
- It allowed us to run multiple terraform projects at once with a single command
- Pass outputs from one terraform project to another using a dependency chain.
- Define a configuration file that tells terraform what application setting template file to apply to an application; we used .tpl files to apply application settings to our Azure compute resources.
- Define a configuration file that tells terraform what variable files to include in your terraform commands
- Allowed us to merge-common input variables with tier-specific input variables with the desired precedence
- It allowed us to consistently name and create state files
Example
Let’s consider the situation where we want to maintain the infrastructure for a system with two major components: an API and a database solution. You must also deploy dev, test, stage, and production environments for this system. Dev and Test environments are deployed to one region, while stage and production environments are deployed to two regions.
We’ve created a preconfigured sample repository to demonstrate how we might handle something like this with Terragrunt. Now, although the requirements and scenario described above may not pertain to you, the preconfigured sample repository should give you a good idea of what you can accomplish with Terragrunt and the benefits it provides in the context of keeping your Terraform code organized. Also, remember that Terragrunt is unopinionated and allows you to configure it in several ways to accomplish similar results; we will only cover a few of the benefits Terragrunt provides, but be sure to check out their documentation site for more information.
To get the most out of the code sample, you should have the following:
– Terraform CLI
– Terragrunt CLI
– An Azure Subscription
– AZ CLI
Run through the setup steps if you need to. This will involve running a mini terraform project to provision a few resource groups in addition to a storage account to store your Terraform state files.
The sample repo contains several top-level directories:
- /_base_modules
- /bootstrap
- /dev
- /test
- /stage
- /prod
- _base_modules – folder contains the top-level Terraform modules that your application will use. There are subfolders for each application type, the API, and storage solution (/api and /sql). For example, there is a subfolder for the API, which contains the terraform code for your API application, and one for SQL, which will contain the terraform code for your storage/database solution; take note of the main.tf, variables.tf, and outputs.tf files in each sub folder. Each application type folder will also contain a .hcl file that contains global configuration values for all environments that consume that respective application type
- [dev/test/stage/prod] – environment folders that contain sub folders for each application type. Each sub folder for each application type will contain Terragrunt configuration files that contain variables and inputs specific to that environment
- bootstrap – a small isolated terraform project that will spin up placeholder resource groups in addition to a storage account used to maintain remote Terraform state files
As mentioned above, there are several .hcl files in a few different places within this folder structure. These are Terragrunt configuration files. You will see one within each sub folder inside the _base_modules directory and one in every sub folder within each environment folder. These files are how Terragrunt knows what terraform commands to use, where to store each application’s remote state, and what variable files and input values to use for your terraform modules defined in the _base_modules directory. Read more about how this file is structured on Gruntwork’s website. With this sample repository, global configurations are maintained in the /_base_modules folder and consumed by configurations in the environment folders.
Let’s go over some of the basic features that Terragrunt offers.
Keeping your Remote State Configuration DRY
I immediately noticed when writing my first bits of Terraform code that I couldn’t use variables, expressions, or functions within the Terraform configuration block. You can override specific parts of this configuration through the command line, but there was no way to do this from code.
Terragrunt allows you to keep your backend and remote state configuration DRY by allowing you to share the code for backend configuration across multiple environments. Look at the /_base_modules/global.hcl file in conjunction with the /dev/Terragrunt.hcl file.
/_base_modules/global.hcl:
remote_state {
backend = "azurerm"
generate = {
path = "backend.tf"
if_exists = "overwrite"
}
config = {
resource_group_name = "shared"
storage_account_name = "4a16aa0287e60d48tf"
container_name = "example"
key = "example/${path_relative_to_include()}.tfstate"
}
}
This file defines the remote state that will be used for all environments that utilize the API module. Take special note of the ${path_relative_to_include} expression – more on this later.
A remote state Terragrunt block that like this:
remote_state {
backend = "s3"
config = {
bucket = "mybucket"
key = "path/for/my/key"
region = "us-east-1"
}
}
Is equivalent to a Terraform block that looks like:
terraform {
backend "s3" {
bucket = "mybucket"
key = "path/to/my/key"
region = "us-east-1"
}
}
To inherit this configuration into a child subfolder or environment folder you can do this:
/dev/api/terragrunt.hcl
include "global" {
path = "${get_terragrunt_dir()}/../../_base_modules/global.hcl"
expose = true
merge_strategy = "deep"
}
The include statement above tells Terragrunt to merge the configuration file found at _base_modules/global.hcl with its local configuration. The ${path_relative_to_include} in the global.hcl file is a predefined variable that will return the relative path of the calling .hcl file, in this case,/dev/api/terragrunt.hcl. Therefore, the resulting state file for this module would be in the example container at dev/api.tfstate. For the SQL application in the dev environment, the resulting state file would be dev/sql.tfstate; look at the _base_modules/sql/sql.hcl file. For the API application in the test environment, the resulting state file would be test/api.tfstate. Be sure to check out all of the built-in functions Terragrunt offers out of the box.
Using the feature just mentioned, we only define the details of the remote state once, allowing us to cut down on code repetition. Read more about the remote_state and include blocks and how you can configure them by visiting the Terragrunt documentation. Pay special attention to merge strategy options, how you can override includes in child modules, and the specific limitations of configuration inheritance in Terragrunt.
Keeping your Terraform Configuration DRY
Merging configuration files does not only apply to remote state configurations – but you can also apply them to the sources and inputs of your modules.
In Terragrunt, you can define the source of your module (main.tf or top-level terraform module) within the Terraform block. Let’s consider the API application:
/_base_modules/api/api.hcl
terraform {
source = "${get_terragrunt_dir()}/../../_base_modules/api"
extra_arguments "common_vars" {
commands = get_terraform_commands_that_need_vars()
required_var_files = [
]
}
}
You’ll notice this is referencing a local path; alternatively, you can also set this to use a module from a remote git repo or terraform registry.
The api.hcl configuration is then imported as a configuration into each environment folder for the API application type:
Ex. /dev/api/terragrunt.hcl
include "env" {
path = "${get_terragrunt_dir()}/../../_base_modules/api/api.hcl"
expose = true
merge_strategy = "deep"
}
Include statements with specific merge strategies can also be overwritten by configurations in child modules, allowing you to configure each environment separately if needed.
Merging inputs before they are applied to your terraform module is also extremely helpful if you need to share variables across environments. For example, all the names of your resources in your project might be prefixed with a particular character set. You can define any global inputs in the inputs section of the _base_modules/global.hcl file. Because Terragrunt configuration files are written in the HCL language, you can also utilize all the expressions and functions you use in Terraform to modify or restructure input values before they are applied. Look at how we are defining the identifier input variable found in both SQL and API modules:
Here is the terraform variable:
/_base_modules/api/variables.tf and /_base_modules/sql/variables.tf
variable "identifier" {
type = object({
primary = string
secondary = string
type = string
})
}
Here is the primary property being assigned from the global env:
/_base_modules/global.hcl
...
inputs = {
identifier = {
primary = "EXAMPLE"
}
}
...
Here is the secondary property being assigned from the dev/dev.hcl file:
/dev/dev.hcl
inputs = {
identifier = {
secondary = "DEV"
}
}
And here is the type property being applied in the module folders:
/_base_modules/sql/sql.env.tf
...
inputs = {
identifier = {
type = "SQL"
}
}
/_base_modules/api/api.hcl
...
inputs = {
identifier = {
type = "API"
}
}
All configurations are included in the environment configuration files with:
include "global" {
path = "${get_terragrunt_dir()}/../../_base_modules/global.hcl"
expose = true
merge_strategy = "deep"
}
include "api" {
path = "${get_terragrunt_dir()}/../../_base_modules/api/api.hcl"
expose = true
merge_strategy = "deep"
}
include "dev" {
path = "../dev.hcl"
expose = true
merge_strategy = "deep"
}
would result in something like:
inputs = {
identifier = {
primary = "EXAMPLE"
secondary = "DEV"
type = "API"
}
}
We utilize this pattern to share variables across all environments and applications within a specific environment without having to declare them multiple times.
It is also important to note that because Terragrunt configuration files are written in the HCL language, you have access to all Terraform’s functions and expressions. As a result, because you can inherit Terragrunt configuration files into a specific environment, you can restructure, merge, or alter input variables before they are sent to terraform to be processed.
Running Multiple Modules at once
You can also run multiple terraform modules with one command using Terragrunt. For example, if you wanted to provision dev, test, stage, and prod with one command, you could run the following command in the root directory:
terragrunt run-all [init|plan|apply]
If you wanted to provision the infrastructure for a specific tier, you could run the same command inside an environment folder (dev, test, stage, etc.). This allows you to neatly organize your environments instead of maintaining everything in one state file or trying to remember what variable, backend, and provider configurations to pass in your CLI commands when you want to target a specific environment.
It is important to note that you can maintain dependencies between application types within an environment (between the SQL and API applications) and pass outputs from one application to another. Look at the dev/api environment configuration file:
/dev/api/terragrunt.hcl
dependency "sql" {
config_path = "../sql"
mock_outputs = {
database_id = "temporary-dummy-id"
}
}
locals {
}
inputs = {
database_id = dependency.sql.outputs.database_id
...
}
Notice that it references the dev/sql environment as a dependency. The dev/sql environment uses the _base_modules/sql application so look at that module, specifically the outputs.tf file.
/_base_modules/sql/outputs.tf
output "database_id" {
value = azurerm_mssql_database.test.id
}
Notice that this output is being referenced in the /dev/api/terragrunt.hcl file as dependency.
The client requirements described earlier in this post proved to be especially difficult to maintain without the benefit of being able to configure separate modules that depend on one another. With the ability to isolate different components of each environment and share their code and dependencies across environments, we could maintain multiple environments effectively and efficiently with different configurations.
Conclusion
Terraform as an IaC tool has helped us reliably develop, maintain, and scale our infrastructure demands. However, because our client work involved maintaining multiple environments and projects simultaneously, we needed specific declarative design patterns to organize our infrastructure development. Terragrunt offered us a simple way to develop numerous environments and components of a given application in a way that was repeatable and distributable to other project pipelines.
There are several features of Terragrunt we did not discuss in this post:
– Before, After, and Error Hooks
– Maintaining CLI flags
We would like to see some of the functionality Terragrunt offers baked into Terraform by default. However, we do not feel like Terragrunt is a final solution; Terraform is rather unopinionated and less concerned with how you set up your project structure, while Terragrunt is slightly more opinionated in your setup. Terragrunt claims to be DRY, but there is still a lot of code duplication involved when creating multiple environments or trying to duplicate infrastructure across regions. For example, creating the folder structure for an environment is cumbersome, especially when you want to add another tier.


