 At the Microsoft BUILD 2017 Day One keynote, Harry Shum announced the ability to customize the vision API. In the past, the cognitive vision API came with a pre-trained model. That meant that as a user, you could upload a picture and have the pre-trained model analyze it. You can expect to have your image classified based on the 2,000+ (and constantly growing) categories that the model is trained on. You can also get information such as tags based on the image, detect human faces, recognize hand-written text inside the image, etc.
At the Microsoft BUILD 2017 Day One keynote, Harry Shum announced the ability to customize the vision API. In the past, the cognitive vision API came with a pre-trained model. That meant that as a user, you could upload a picture and have the pre-trained model analyze it. You can expect to have your image classified based on the 2,000+ (and constantly growing) categories that the model is trained on. You can also get information such as tags based on the image, detect human faces, recognize hand-written text inside the image, etc.
But what if you wanted to work with images pertinent to your specific business domain? And what if those images fall outside of the 2,000 pre-trained categories? This is where the custom vision API comes in. With the custom vision API, you can train the model on your own images in just four steps:
- Create a custom vision API project and select from a list of available domains (Generic, Food, Landmarks etc.). By selecting a domain, you can take advantage of the pre-built classifier and large image database (i.e. Bing) to improve the your training set. As you will see later, user are expected to upload a small number of images to train the custom vision API.
- Upload your custom images – say pictures of flowers with appropriate “labels” or names of the flowers such as Daisies”, “Daffodils”, and “Dahlias”.
- Train the custom model.
- Evaluate the trained model by invoking a REST API (this process sets up a continuous feedback loop for improving the trained model).
It is important to note that custom vision API is focused image classification: the ability to detect if an image is of a particular object. It does not yet address object detection: the ability to detect objects within the image. You can start with as little as 50 images for each object type.
We decided to apply to the custom vision API to a problem of detecting roof types. We want to show a picture of roof and have the vision API return to us what type of roof is in the photo.
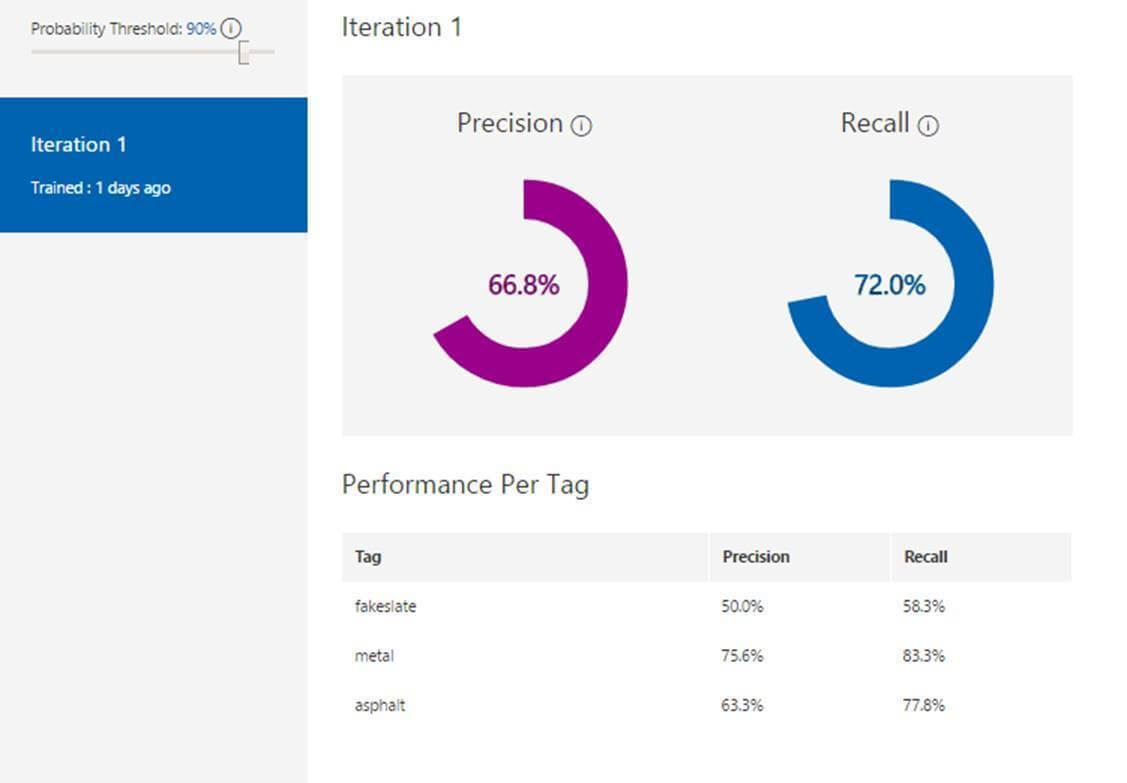
We trained the custom vision API by uploading images of three types of roofs: fakeslate, asphalt and metal (please see table below). Then we used the prediction API to test images. The custom vision API returns the probability that the image is of certain type.The results of the prediction API are depicted in the first row. Also look at the overall precision (true positives / true positives + false positives) and recall (true positives / true positives + false negatives) shown the bottom of the table.
Clearly we can continue to improve the results by training the model on additional images.
Note: Thanks to Nasir Mirza for setting up the experiment.