Reader Summary
This is part of a three-part series on Microsoft Fabric strategy. Other parts will cover AI, ontologies, and the agentic future of Fabric as well as dbt’s new first-class role in Fabric.
Most legacy Power BI environments carry more knowledge debt than technical debt. The business logic is buried in DAX measures nobody documented, the ETL lives in Power Query M transforms that only one person understands, and the implicit dependencies between dataflows, semantic models, and reports exist nowhere except in institutional memory. When the people who built these systems move on, the knowledge goes with them. This post covers how we use a specification-driven approach with AI coding agents to systematically decompose legacy Power BI projects and rebuild them as enterprise-grade dbt projects in Microsoft Fabric. The result is not just a platform migration. It is a maturity leap from undocumented, untested, tribal-knowledge-driven BI to spec-driven, documented, tested, lineage-traced analytics engineering, where the migration itself produces the governance layer that never existed before.

The Hidden Cost of Legacy Power BI
Every enterprise data team has at least one Power BI environment that nobody can fully explain. The business logic is buried in DAX measures that were never documented. The ETL lives in Power Query M transforms that only one person understands. The dependencies between dataflows, semantic models, and reports exist nowhere except in institutional memory. The reports work. The numbers are trusted—mostly. But when the people who built these systems move on, the knowledge goes with them.
This is not technical debt in the traditional sense. What most legacy Power BI environments carry is knowledge debt: the gap between what the system does and what anyone can explain about why it does it. No tests validate the DAX measures. No documentation connects a transform to the business requirement it satisfies. No lineage shows which upstream change will break which downstream report. Every month that passes, more institutional knowledge decays, and every new requirement gets layered onto a foundation nobody can fully explain. The question is not whether to modernize. It is whether you can afford to keep deferring it.
A note on scope. This post focuses on Power BI workspace environments—the most common starting point for enterprise modernization. Estates involving Power BI Report Server or SSAS tabular models carry additional discovery and conversion considerations. The principles are the same, but the surface area is larger and the tooling dependencies are different.
Spec-Driven Migration
The instinct when approaching a legacy migration with AI is to point a coding agent at the existing artifacts and say “translate this.” That produces output, but not engineering. You get SQL that is technically equivalent to the DAX it replaced, but without the naming conventions, model layering, testing standards, or documentation that make a dbt project maintainable. You have traded one black box for another.
Our approach at AIS is specification-driven, following the methodology that GitHub formalized with their open-source Spec Kit and that Brent Wodicka outlined in his recent post on how AIS is rethinking software development with AI. The process follows a structured workflow: specify the requirements and constraints first, plan the target architecture, research the existing artifacts and dependencies, break the work into discrete tasks, then implement with AI agents operating within those guardrails. The specification defines model layering conventions, naming standards, testing requirements, documentation expectations, and the target data architecture—staging, intermediate, and marts layers following medallion principles. dbt is the framework that makes this architecture enforceable: ref()-based dependencies give you lineage, schema YAML gives you documentation, and built-in testing gives you validation—capabilities that do not exist in the legacy environment at any level. This means the migration is not a one-to-one swap of DAX for SQL. It is an opportunity to establish mature analytics engineering patterns so that every model produced follows consistent conventions. The specification accelerates both the initial conversion and every sprint that comes after it.
The Reverse-Engineering Process

The migration decomposes the legacy environment layer by layer, with each layer guided by the specification. This is not a single-pass translation. It is structured decomposition that preserves business intent while rebuilding it in a framework that supports testing, documentation, and lineage from the start.
Canonical data sources and schema discovery comes first. Before any artifact conversion begins, the process maps the upstream data landscape: databases, schemas, APIs, and file sources that feed the legacy environment. This discovery is one of the key deliverables of the migration, not just a prerequisite. The resulting source catalog—with documented table relationships, column types, referential integrity, and naming patterns—provides grounding context for every conversion decision that follows. In legacy environments, this map existed only in people’s heads. After discovery, it is explicit, version-controlled, and traceable through the dbt lineage graph.
Power Query M transforms become dbt staging models. The M code in each dataflow step is decomposed into its functional intent and re-expressed as SQL. The agent does not do line-by-line syntax translation. It identifies what the transform accomplishes—type casting, column renaming, filtering, joining, deduplication—and writes the equivalent SQL following the staging patterns in the specification.
Dataflow lineage becomes the dbt DAG. The implicit dependency graph—which dataflow feeds which dataset, which dataset feeds which report—is made explicit through dbt’s ref() function. Dependencies that existed only in people’s mental models become visible, testable, and enforceable.
DAX measures become SQL in the marts layer. DAX is the hardest layer because it often encodes business rules that were never specified anywhere else. A CALCULATE expression with complex filter context is not just a SQL pattern—it is a business decision about how a metric should be computed under specific conditions. The specification-driven process extracts these rules, converts them into SQL-based dbt models in the marts layer, and documents the business logic the original DAX was implementing.
Semantic model relationships become dbt schema YAML. The joins, hierarchies, and display folders in the Power BI semantic model map to dbt’s schema YAML as relationship definitions, column descriptions, and documentation. This metadata was locked inside the Power BI model definition. After migration, it is version-controlled, reviewable, and consumable by downstream systems including Fabric’s ontology layer.
Documentation as a First-Class Outcome
The most common reaction when people see the output of a spec-driven migration is not about the SQL. It is about the documentation. The legacy environment had none. The migrated dbt project has model-level descriptions explaining what each model does and why, column-level documentation capturing business definitions, test coverage validating business rules, a lineage graph from source to consumption, and conversion notes explaining how each artifact was handled. This was generated as part of the migration because the specification required it. Every business rule extracted from DAX is described in plain language alongside the SQL that replaced it.
The practical impact is significant. New team members onboard by reading the dbt project instead of tracking down the person who built the original reports. Data quality issues trace from a failing test back through the lineage to the source. Stakeholders review business rules in schema YAML without reading SQL or DAX. The migration extracted institutional knowledge from people’s heads and codified it in a structured, testable, version-controlled format for the first time. And because business logic now lives in a governed data layer rather than the visualization layer, it serves broader consumption patterns—not just Power BI reports, but data science workloads, APIs, and the agentic AI scenarios we explored in Part 1 of this series. This connects directly to the dbt project quality guidance in Part 2: the most valuable investment right now is documentation, testing, and consistent model layering, because that work positions your project for Fusion, ontology integration, and agent-consumable data. A spec-driven migration produces all of that as a natural byproduct.
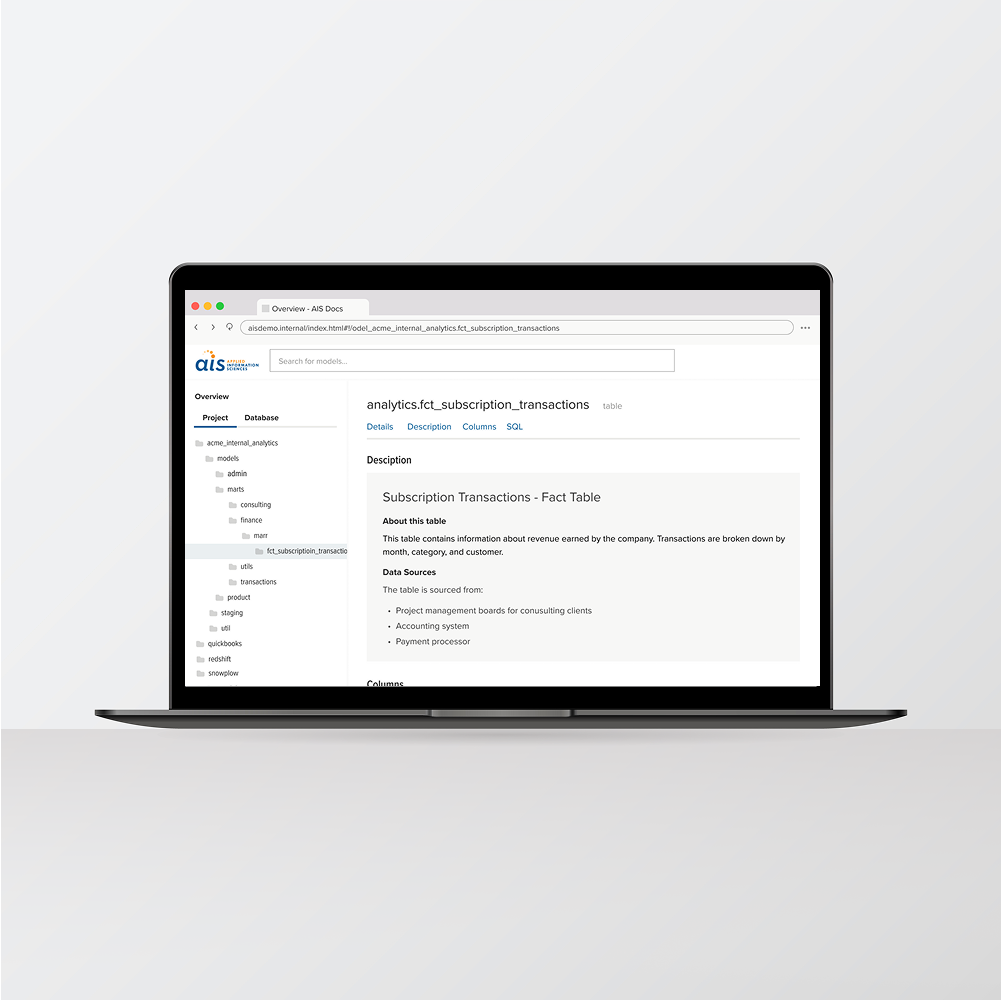

Documentation, lineage, and test coverage generated as a byproduct of the spec-driven migration.
What the Agent Gets Wrong (and What Still Needs You)
Credibility requires honesty about limitations. AI coding agents are remarkably capable at structured decomposition and code conversion, but there are categories of work where they consistently need human review, and the specification is designed to flag these rather than silently guess.
Complex DAX filter context. DAX’s evaluation context—especially CALCULATE with nested filters, ALL/ALLEXCEPT, and row-to-filter transitions—lacks a straightforward SQL equivalent. While most common patterns are supported, deeply nested context transitions need a practitioner to confirm the SQL matches business requirements. These cases are marked as “requires human validation” with the specific pattern and associated rule identified.
Performance patterns. A DAX measure that performs well in VertiPaq may produce correct but slow SQL. Patterns that rely on columnar compression or lazy evaluation need different approaches in the Fabric Warehouse engine—aggregation strategies, materialization choices, or pre-computation that a data engineer needs to decide based on actual query volumes.
Organizational context. An agent can tell you what a DAX measure computes. It cannot tell you why the business cares, who the stakeholders are, or what would happen if the number changed by two percent. That context determines testing thresholds, alerting requirements, and documentation priorities. The spec-driven approach captures these decisions through structured conversations with business stakeholders alongside the technical migration.
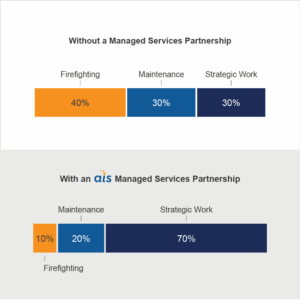
Every conversion includes a confidence classification. The goal is not to eliminate the need for skilled practitioners. It is to focus data engineers on architecture and pipeline optimization, DataOps teams on validation and quality enforcement, and data analysts on the domain knowledge review that only they can provide—rather than having any of these roles consumed by mechanical conversion work.
The analyst’s role evolves, it does not disappear. A common concern with AI-driven migration is that it replaces the people who understand the data best. The spec-driven approach does the opposite. After the agent produces converted models, the data analyst is the human in the loop who validates that business rules survived translation—confirming that a net collection rate still attributes payments by post date, or that a readmission calculation respects the CMS reporting window. The analyst becomes the primary author of the business context documentation the specification requires: plain-language descriptions of what each metric means and what thresholds indicate a problem. The migration redefines the role from someone who manually maintains DAX measures to an analytics engineer who governs business logic, reviews agent output for domain accuracy, and owns the semantic layer that both reports and AI agents consume.
The Net Result and What Comes Next
The starting point was a legacy Power BI environment: functional but opaque, untested, undocumented, and held together by institutional knowledge that was already decaying. The endpoint is an enterprise-grade dbt project in Microsoft Fabric: version-controlled, tested, documented, with full lineage and business rules expressed in plain language alongside the code. The migration path is a maturity leap, not a platform swap.
A practical note on execution today. Fabric’s native dbt integration is still maturing—as we discussed in Part 2, the full story around source control and Fusion is six to twelve months out. But this methodology does not depend on Fabric-native execution. Teams can run dbt Core with GitHub Actions against Fabric warehouses today. One AIS client in healthcare is already doing exactly this: dbt Core against the warehouse architecture we designed, with canonical layering, documented SOPs, and no ad hoc scripts—the same mature pattern we previously implemented on Snowflake. The investment pays back immediately regardless of execution path.
The dbt project metadata this process creates—model descriptions, column definitions, test coverage, lineage—is exactly what Fabric IQ’s ontology layer needs to make data agent-consumable. The schema discovery, business rule extraction, and relationship mapping are the raw inputs for ontology development. Organizations that follow this methodology are not just modernizing their transformation layer. They are generating the semantic foundation that Part 1 of this series argues is the prerequisite for agentic AI.
For organizations evaluating this path, the question is not whether AI can convert DAX to SQL. It can. The question is whether you have the discipline to define what good looks like before you start, and the expertise to validate the results where human judgment is required. The specification is what separates a migration that produces working code from a migration that produces an enterprise asset.
Ready to assess your legacy Power BI environment for migration? Contact us to discuss a spec-driven migration assessment and see how the process works with your specific environment.