






Azure Cognitive Services is Microsoft’s offering for enabling artificial intelligence (AI) applications in daily life, a collection of AI services that currently offer capabilities around speech, vision, search, language, and decision. While these services are easy to integrate and consume in your business applications, they bring together powerful capabilities that apply to numerous use cases.
Azure Personalizer is one of the services in the suite of Azure Cognitive Services, a cloud-based API service that allows you to choose the best experience to show to your users by learning from their real-time behavior. Azure Personalizer is based on cutting-edge technology and research in the areas of Reinforcement Learning and uses a machine learning (ML) model that is different from traditional supervised and unsupervised learning models.
This blog is divided into three parts. In part one, we will discuss the core concepts and architecture of Azure Personalizer Service, Feature Engineering, and its relevance and importance. In part two, we will go over a couple of use cases in which Azure Personalizer Service is implemented. Finally, in part three, we will list out recommendations and capacities for implementing solutions using Personalizer.
Core Concepts & Architecture
At its core, Azure Personalizer takes a list of items (e.g. list of drop-down choices) and their context (e.g. Report Name, User Name, Time Zone) as input and returns the ranked list of items for the given context. While doing that, it also allows feedback submission regarding the relevance and efficiency of the ranking results returned by the service. The feedback (reward score) can be automatically calculated and submitted to the service based on the given personalization use case.
Azure Personalizer uses the feedback submitted for the continuous improvement of its ML model. It is highly essential to come up with well thought out features that represent the given items and their context most effectively as per the objective of personalization use case. Some of the use cases for Personalizer are content highlighting, ad placement, recommendations, content filtering, automatic prioritizing, UI usability improvements, intent clarification, BOT traits and tone, notification content & timing, contextual decision scenarios, rapidly changing contents (e.g. news, live events), etc.
There is a wide range of applications of Personalizer Service, in general, every use case where a ranking of options makes sense. Its application is not limited to a simple static list of items to be ranked, one is limited as much as the ability of feature engineering to define an item and its context, which can be effectively anything simple to quite complex. What makes Personalizer scope wide and effective are:
- Definition of items (called as Actions) and their context with the features
- No dependency on prior historically labeled data
- Real-time optimization with consumption of feedback in the form of reward scores
- Personalizer Service has this notion of exploitation (utilizing ML model recommendation) as well as exploration i.e. using an alternate approach (based on Epsilon Greedy algorithm) to determine the item ranking instead of ML model recommendation
- Exploration ensures the Personalizer continues to deliver good results even in the changing user behavior and avoids model stagnation, drift, and ultimately lower performance
The following diagram shows the architectural flow and components of Personalizer Service and follows with a description of each of the labeled component.
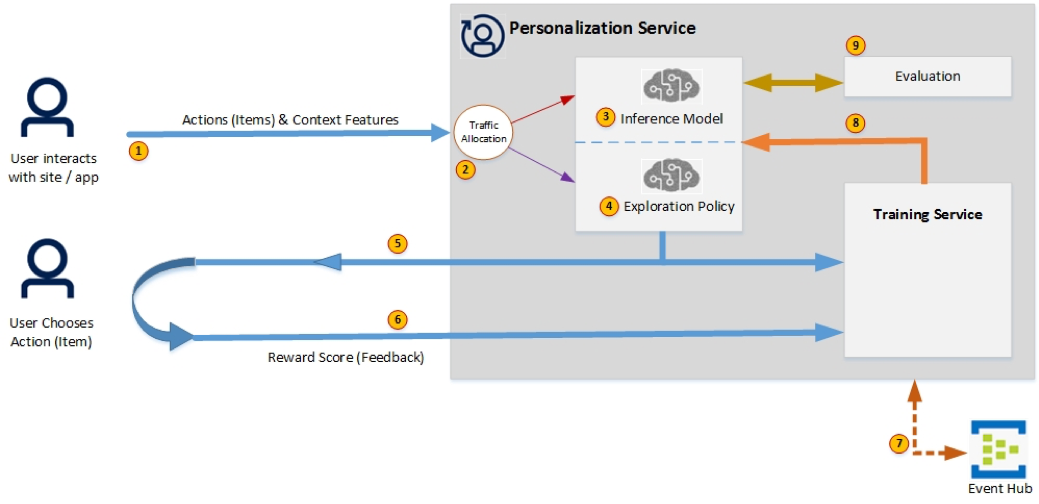
- The user interacts with the site/application, features related to the actions and context are sent to the Personalizer in a Rank call.
- Personalizer decides whether to exploit the current model or explore new choices. Explore setting defines the percentage of Rank calls to be used for exploring.
- Personalizer currently uses Vowpal Wabbit as the foundation for machine learning. This framework allows maximum throughput and lowest latency when calculating ranks and training the model with all events.
- Personalizer exploration currently uses an algorithm called epsilon greedy to discover new choices.
- Ranking results are returned to the user as well as sent to the EventHub for later correlation with reward scores and training of the model.
- The user chooses an action (item) from the ranking results, and the reward score is calculated and submitted to the service in a single or multiple calls using the Personalizer Rewards API. The total reward score is a value between -1 to 1.
- The ranking results and reward scores are sent to the EventHub asynchronously and correlated based on EventID. ML model is updated based on correlation results and the inference engine is updated with a new model.
- Training service updates the AI model based on the learning loops (cycle of ranking results and reward) and updates the engine.
- Personalizer provides an offline evaluation of the service based on the past data available from the ranking calls (learning loops). It helps determine the effectiveness of features defined for actions and context. This can be used to discover more optimized learning policies.
Learning policy determines the specific hyperparameters for the model training. These can be optimized offline (using offline evaluation) and then used online. These can be imported/exported for future reference, re-use, and audit.
Feature Engineering
Feature engineering is the process of producing such data items that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data, it is turning of raw input data into things that model can understand. Estimates show that 60 – 70% of the ML project time is spent in feature engineering.
Good quality features for context and actions is the foundation that determines how effective Personalization Service will perform predictions and drive the highest reward scores; due attention needs to be paid to this aspect of implementing Personalizer. In the field of data science, feature engineering is a complete subject on its own. Good features are characterized as:
- Be related to the objective
- Be known at prediction-time
- Be numeric with meaningful magnitude
- Have enough examples
- Bring human insight into the problem
It is recommended to have enough features defined to drive personalization, and these be of diverse densities. High-density features help Personalizer extrapolate learning from one item to another. A feature is dense if many items are grouped into few buckets e.g. nationality of a person, and sparse if items spread across a large number of buckets e.g. book title. One of the objectives of the feature engineering is to make features denser, e.g. timestamp down to the second is very sparse, it could be made dense (effective) by classifying into “morning”, “midday”, “afternoon” etc.
Personalizer is flexible and adaptive to the unavailability of some features for some items (actions), or addition or removal of features over time. For Personalizer, features can be categorized and grouped into namespaces as long as they are valid JSON objects.
In the next part of this blog post, we will go over a couple of use cases for which Personalizer was implemented, looking at features, reward calculation, and their test run results. Stay tuned!

