 Amazon Web Services (AWS) provides an extremely flexible set of services for hosting web applications in the cloud with a web-based console for selecting options to quickly provision a set of IT resources. This post will explore the various aspects of hosting a custom .NET web application in AWS, focusing on high-availability options and disaster recovery scenarios and how to do so under cost constraints.
Amazon Web Services (AWS) provides an extremely flexible set of services for hosting web applications in the cloud with a web-based console for selecting options to quickly provision a set of IT resources. This post will explore the various aspects of hosting a custom .NET web application in AWS, focusing on high-availability options and disaster recovery scenarios and how to do so under cost constraints.
When building a solution in AWS you have to understand the difference between affinity and availability, and the terminology that Amazon uses. We will define affinity as the physical location of resources within a data center and availability as the isolation of resources for disaster recovery scenarios.
The AIS solution I’ll reference throughout this post uses a Virtual Private Cloud (VPC) to enable our engineers to develop a multi-tiered application within a private sub-netted network split across two availability zones. The VPC as defined by Amazon allows for “… you to create a virtual network topology—including subnets and route tables—for your Amazon Elastic Compute Cloud (Amazon EC2) resources.” The use of a VPC ensures you have high affinity for your EC2 resources. Availability zones refer to the geographically separated data centers Amazon uses for hosting EC2 resources. Therefore, your disaster recovery architecture must account for placement of EC2 resources in different Availability Zones.
High Availability vs. Disaster Recovery in AWS
To muddy the terminology waters further, we have the concept of high availability, where the effects of hardware or software failure are essentially masked and downtime for end users reduced, such as in Microsoft’s SQL Server. Our solution had to address the issue of high availability and allow for a swift recovery in the event of a disaster or failure of EC2 resources in one availability zone. A high-level picture of what we needed to achieve is shown below.
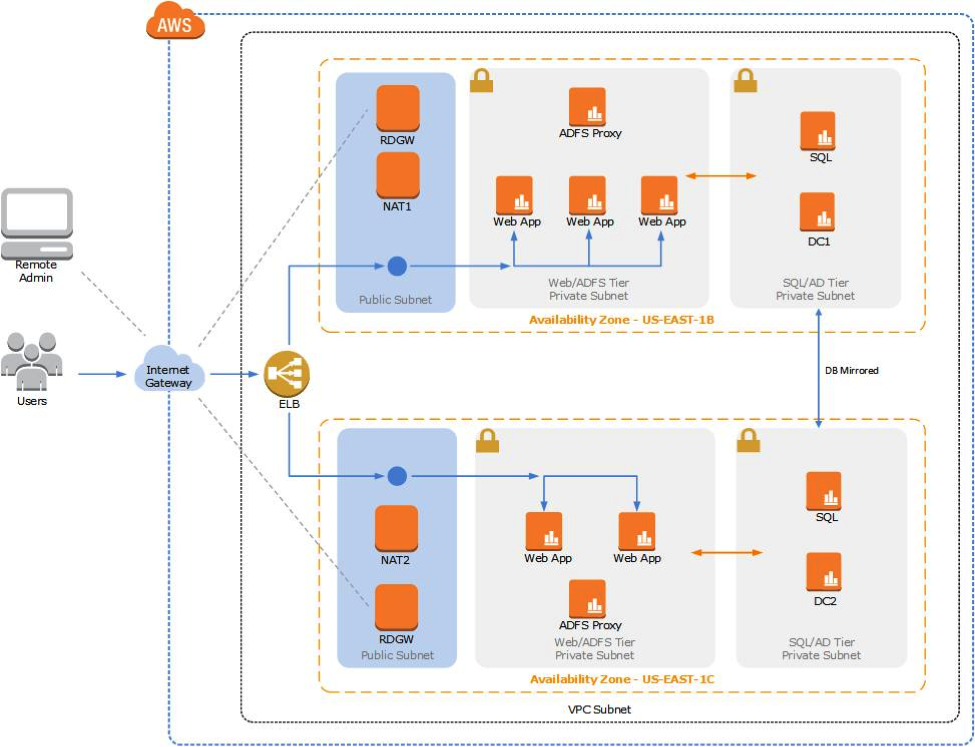
To achieve a level of high availability for the data tier, we made use of SQL Server mirroring across the two availability zones. However, due to costs associated with running SQL in a high safety mode we chose to set up mirroring in a warm standby mode.
To achieve high availability for the web tier we made use of the Amazon’s Simple Storage Service (S3). Each web application server was set up with a mapped drive to a single S3 bucket (a term which explains what basically amounts to a slice of S3) and the asp.net files were placed on this drive. We then load balanced our web application servers using an Elastic Load Balancer with an elastic IP.
Choosing Instance Types in AWS, When to Use Them & Availability Zones
When you first start out creating EC2 resources you have a choice to make concerning instance types. Instances are simply virtual machines that run within the Elastic Cloud Compute infrastructure. There are many different types of instances based on your computing needs. Additionally, Amazon offers Spot instances, On-Demand instances and Reserved instances.
The main difference between these three types is that with spot instances, you are essentially bidding for spare computing capacity. However, with On-Demand and Reserved instances you are paying for a longer-term investment in a dedicated resource, similar to renting an entire server from a web hosting company. On-Demand resources allow you to pay an hourly fee for operating a server with no long-term contract, while Reserved instances are purchased in one- or three-year commitments with an upfront fee but lower hourly costs.
Amazon’s explanation of when to use Spot Instances: “Spot Instances can significantly lower your computing costs for time-flexible, interruption-tolerant tasks.” On-Demand instances are recommended for applications with uninterruptible workloads that are short in duration and unpredictable spikes of activity. For example, if you were testing how a custom application would perform in EC2, you would choose these types of instances. If you want a quick way to weigh costs, this website provides a nice tool for comparing prices.
For our scenario we could not make use of Spot Instances, because our application had to be fault tolerant and highly available, and we had decided to build out a VPC. We were committed to Reserved instances.
Disaster Recovery Scenarios
To continue the story with the AIS solution, a decision was made to use a warm standby disaster recovery solution to minimize costs and recovery time. However, you could achieve a hot standby level of disaster recovery making use of a high availability SQL Server implementation, which would involve adding a third availability zone with a witness server and an instance to serve as a automation script server. Furthermore, using the Amazon Elastic Load Balancing API, you could easily script the addition and removal of instances from your elastic load balancer.
Cost Savings of Reserved Instances vs. Spot Instances
For applications that are built to be loosely coupled and interruption tolerant, choosing Spot instances makes sense. Especially when combined with a universally accessible storage solution such as S3, you can begin to achieve economies of scale as your infrastructure scales out to meet demand.
However, for a typical ASP.NET web application that is resource intensive and must achieve high levels of performance (plus meet strict levels of security such as encryption of data), your choice of instance type should be a Reserved instance. This gives you the flexibility to customize your platform to meet these needs over a longer period of time without concern for the variability of an on-demand set of resources. Amazon provides some estimates of the total return on investment savings possible when comparing Reserved to On-Demand. For heavily-utilized applications, it makes sense to choose a long-term Reserved instance.
EBS vs. S3 and Glacier as Storage Solutions
Amazon provides several services for data storage for use with your EC2 instances, among these are the Elastic Block Store (EBS) and Amazon S3 (as explained above). In addition, for extremely long-term data storage similar to offsite options, Amazon’s Glacier product is a very economical alternative.
Amazon defines EBS volumes as “… network-attached, and persist independently from the life of an instance.” They can be attached to instances in sizes ranging from 1GB to 1TB and provisioned with a certain level of IOPS to meet the demands of your application. Amazon explains the S3 service as “storage for the Internet” and for most cases, this flexibility works quite well. You can get an overview of pricing here.
There are some cases where using EBS backed volumes attached directly to your instance provide performance benefits that are not achievable through the use of S3. In particular, highly intensive read/write operations will suffer a performance hit when making sole use of an S3 bucket for storage. Additionally, large file read operations tend to perform better on EBS-backed volumes. In these cases, your application should use an EBS volume and possibly consider a provisioned IOPS volume.
Automation of Instances to Reduce Monthly Costs
Given that the AIS solution has a warm standby solution for disaster recovery, there are a number of steps you can take to reduce costs. One of these is to automate the snapshot process for instances each month to allow for a quick recovery scenario. Chris Hettinger has an excellent set of videos available here on the AIS blog which demonstrate how this is done.
Other areas to target for automation are the actual number of hours each instance runs in the warm standby availability zone. Amazon now provides a convenient method through CloudWatch for shutting down an underutilized instance when CPU utilization hits a benchmark you set.
Conclusion
Planning for a disaster recovery scenario in AWS requires a thorough understanding of the operational costs, as well as the startup costs for different types of instances. You should consider the needs of the application architecture prior to committing to any one path and if possible, test your application’s performance on a set of “disposable” On-Demand instances. The flexibility with which you can stand up and tear down an infrastructure is one of the benefits to hosting your application inside Amazon Web Services.
The key areas to manage for costs are instance type, data storage needs and operational running time for your disaster recovery resources. You can effectively control some of these costs through automation, such as powering down underutilized instances, moving data backups to longer term, lower-priced storage options and testing new applications with on-demand resources before committing to a longer-term investment.