Web development is arguably the most popular area of software development right now. Software developers can make snappy, eye-catching websites, and build robust APIs. I’ve recently developed a specific interest in a less discussed facet of web development: web scraping.
Web scraping is the process of programmatically analyzing a website’s Document Object Model (DOM) to extract specific data of interest. Web scraping is a powerful tool for automating certain features such as filling out a form, submitting data, etc. Some of these abilities will depend if the site allows web scraping or not. One thing to keep in mind, if you want to web scrape, is that some websites will be using cookies/session state. So some automation tasks might need to abide by the use of the site’s cookies/session state. It should go without saying, but please be a good Samaritan when web scraping since it can negatively impact site performance.
Getting Started
Let’s get started with building a web scraper in an Azure Function! For this example, I am using an HTTP Trigger Azure Function written in C#. However, you can have your Azure Function utilize a completely different trigger type, and your web scraper can be written in other languages if preferred.
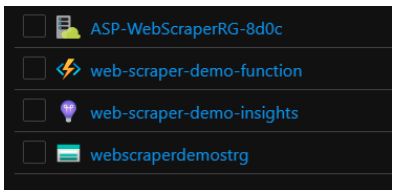
Here is a list of Azure resources that were created for this demo:
Before we start writing code, we need to take care of a few more things first.
Let’s first select a website to scrape data from. I feel that the CDC’s COVID-19 site is an excellent option for this demo. Next, we need to pick out what data to fetch from the website. I plan to fetch the total number of USA cases, new USA cases, and the date that the data was last updated.
Now that we have that out of the way, we need to bring in the dependencies for this solution. Luckily, there is only one dependency we need to install. The NuGet package is called HtmlAgilityPack. Once that package has been installed into our solution, we can then start coding.
Coding the Web Scraper
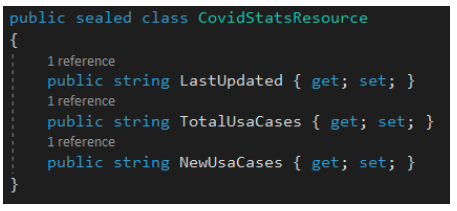
Since the web scraper component will be pulling in multiple sets of data, it is good to capture them inside a custom resource model. Here is a snapshot of the resource model that will be used for the web scraper.
Now it’s time to start coding the web scraper class. This class will utilize a few components from the HtmlAgilityPack package that was brought into the project earlier.
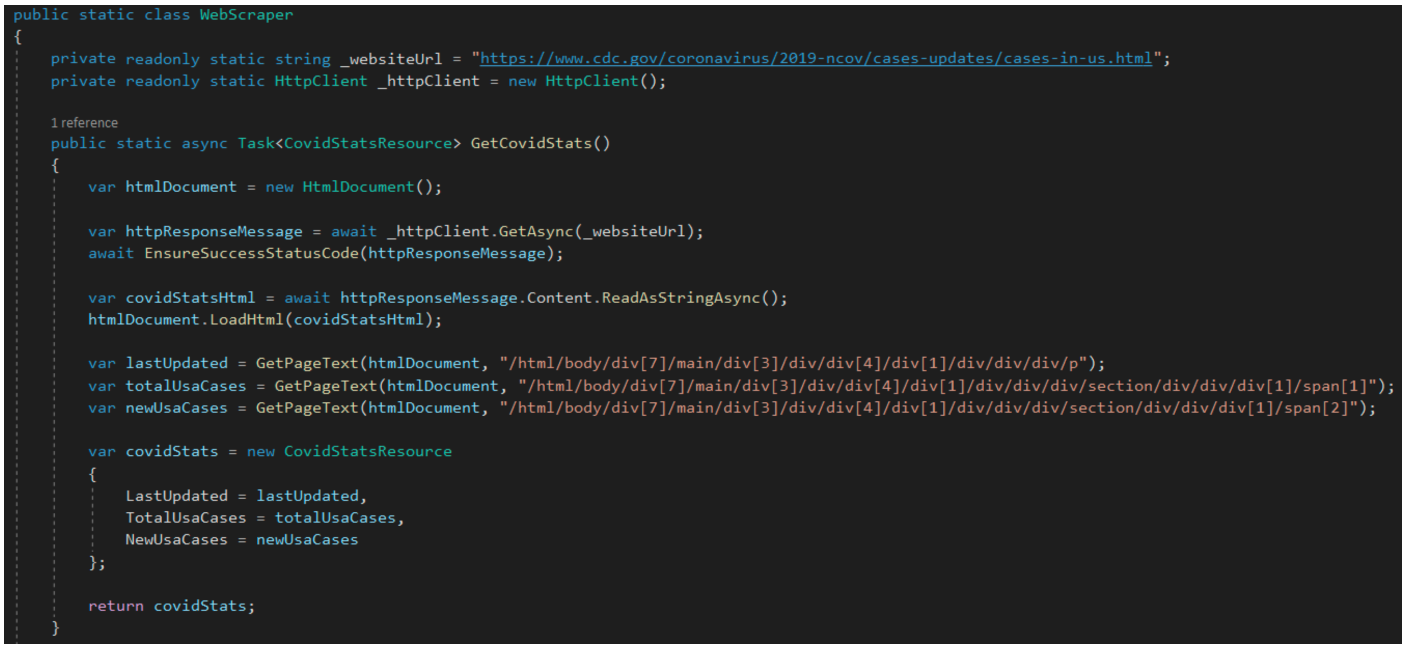
The web scraper class has a couple of class-level fields, one public method, and a few private methods. The method “GetCovidStats” performs a few simple tasks to get our data from the website. The first step is setting up an HTML document object that will be used to load HTML and parse the actual HTML document we get back from the site. Then, there is an HTTP call out to the website we want to hit.
Right after that, we ensure the call out to the website results in a success status code. If not, an exception is thrown with a few details of the failing network call.

We then load the HTML that we received back from the network call into our HTML document object. There are several calls to a method that will perform the extraction of the data we are looking for. Now you might be wondering what those long strings are in the method call. Those are the full xpaths for each targeted HTML element. You can obtain them by opening the dev tools in your browser, selecting the HTML element, and right-clicking it in the dev tools. From there, select “copy full xpath”.

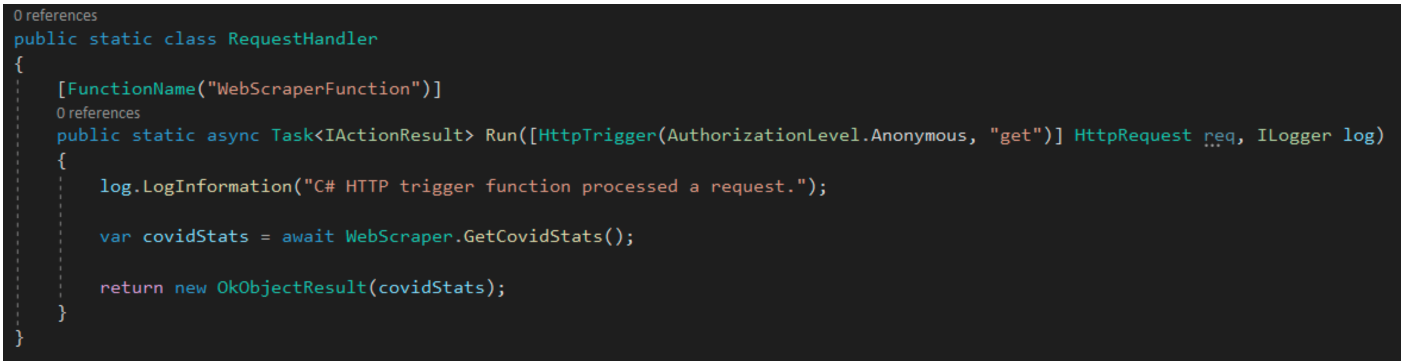
Next, we need to set up the endpoint class for our Azure Function. Luckily for us, the out of the box template sets up a few things automatically. In the endpoint class, we are merely calling our web scraper class and returning its results to the client calling the Azure Function.
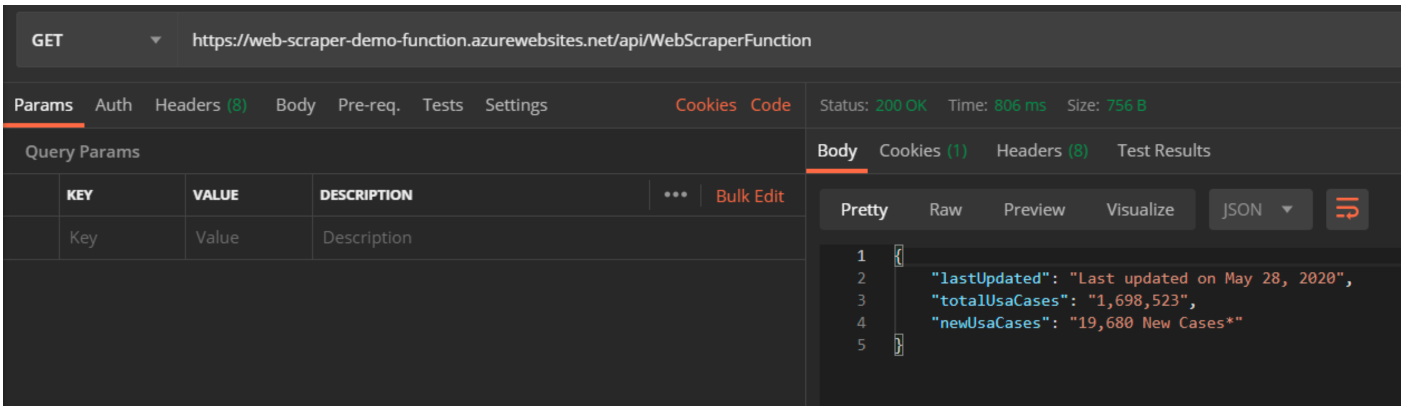
Now comes time to test out the Azure Function! I used Postman for this, and these are the results.
Closing Thoughts
Overall, web scraping can be a powerful tool at your disposal if sites do not offer APIs for you to consume. It allows you to swiftly grab essential data off of a site and even automate specific tasks in the browser. With great power comes great responsibility, so please use these tools with care!