






Relational database source control, versioning, and deployments have notoriously been challenging. Each instance of the database (Dev, Test, Production) can contain different data, may be upgraded at different times, and are generally not in a consistent state. This is known as database drift.
Traditional Approach and Challenges
Traditionally, to move changes between each instance, a one-off “state-based” comparison is done either directly between the database or against a common state like a SQL Server Data Tools project. This yields a script that has no direct context to changes being deployed and requires a tremendous effort to review to ensure that only the intent of the changes being promoted/rolled back is included. This challenge sometimes leads to practices like backing up a “known good copy” aka production and restoring it to lower tiers. For any but the smallest applications and teams, this raises even more challenges like data governance and logistics around test data. These patterns can be automated, but generally do not embrace the spirit of continuous integration and DevOps.
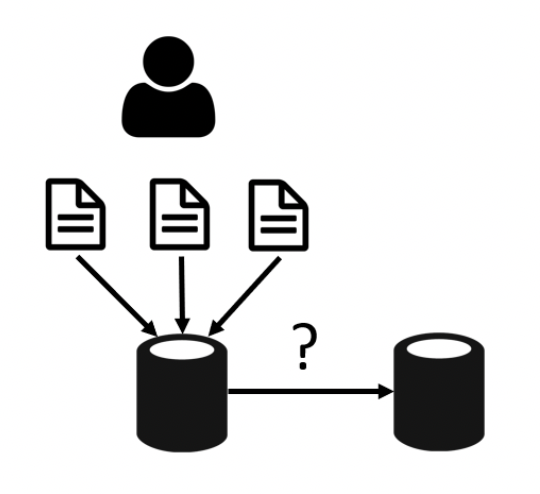
For example, the above three changes could be adding a column, then adding data to a temporary table, and the third populating the new column with the data from the temporary table. In this scenario it isn’t only important that a new column was added, it is also how the data was added. The context of the change is lost and trying to derive it from the final state of the database is too late in the process.
DevOps Approach
Architecturally, application persistence (a database) is an aspect or detail of an application, so we should treat it as part of our application. We use continuous integration builds to compile source code into artifacts and promote them through environments. Object-Relational Mapping (ORM) Frameworks like Entity Framework and Ruby on Rails have paved the way out with a “migrations” change-based approach out of necessity. This same concept can be used for just the schema with projects like FluentMigrator. At development time the schema changes to upgrade and rollback are expressed in the framework or scripted DDL and captured in source control. They are compiled and included in the deployment artifact. When the application invokes a target database, it identifies the current version and applies any changes up or down sequentially to provide deterministic version compatibility. The application is in control of the persistence layer, not the other way around. It also forces developers to work through the logistics (operations) of applying the change. This is the true essence of DevOps.
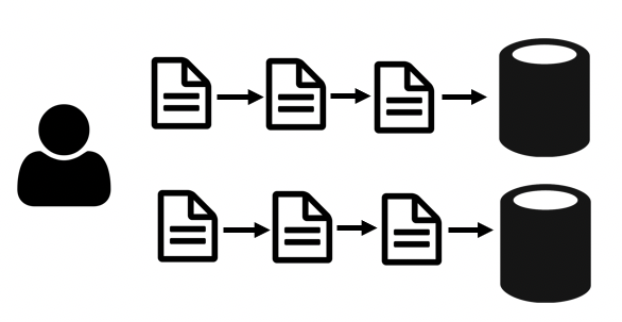
In the same example above, the three changes would be applied to each database in the same sequence and the intent of the change would be captured in both.
Summary
In summary, a migrations-based approach lends itself to a DevOps culture. It may take some additional effort up front to work through and capture how changes should be applied, but it allows all aspects of the database deployment process to be tested throughout a project lifecycle. This promotes repeatability and ultimately the confidence needed to perform frequent releases.

